Why We're Building A Policy Machine
The following is adapted from an internal whitepaper I wrote last year, pitching a platform-wide security enhancement that we’re now implementing. Medidata has complex and evolving access control requirements. To manage them, we’re drawing on a new, open standard–the Policy Machine–from the Computer Security Division at NIST.
Access Control Requirements in the Clinical Cloud
Medidata is powered by the Clinical Cloud, a collection of proprietary RESTful web services managing clinical data and metadata. Each service must make a variety of authentication (who am I?) and authorization (what I am I allowed to do?) determinations. Despite their various and distributed nature, it is essential to make these determinations in a consistent manner across the entire platform. If individual services implement access control independently, an oversight will inevitably occur, and one of the hundreds of routes we expose will be insufficiently protected. The Open Web Application Security Project (OWASP) lists “Failure to Restrict URL Access” among its top ten security risks and mandates that it be mitigated via a “centralized mechanism (including libraries that call external authorization services) for protecting access to each type of protected resource.”
We therefore need a single service powerful enough to fulfill the access control requirements for every element of the Clinical Cloud, with client libraries compatible with all Clinical Cloud services. In particular, this mechanism must:
- Be role-based. Our customers define their authorization requirements by assigning roles to their users and permissions to those roles. An attempt to map these requirements onto any non-role-based internal representation would be complex and likely doomed.
- Incorporate both human and automated users. We need to allow some apps to take a restricted set of actions independently of users, and others to act on behalf of humans. For example, we will we need to control which apps can publish to, and which can subscribe to, a given message queue.
- Allow users to be assigned different roles for different instances of the same resource type. The typical case is that a user is a Principal Investigator for one or more studies, but has no roles for other studies. In many cases, a user may also have a different role for another study. This problem of maintaining separate access control lists for different objects is known as “horizontal” access control. The addition of this requirement already moves us beyond vanilla Role-Based Access Control.
- Allow a single role assignment to be “inherited” by associated resources. For example, in our data model a Study object has many “StudySites”, medical facilties participating in the study. A manager role on a Study could grant the ability to view details of its associated StudySites, and so on with arbitrary levels of nesting.
- Be configurable on a resource-to-resource basis. We need to be able to provide a default “Configuration Type” that can be modified for different client divisions or different studies. A client should be able to configure access control through a web-based user interface without needing detailed information about the workings of our platform. Changes to the configuration of a live resource should take automatic effect on that resource.
- Allow a user with multiple roles to limit their authorizations to those granted by one role. A user with both the Principal Investigator and Clinical Research Associate roles should be able to choose to “act as” a Clinical Research Associate only, hiding actions that are only granted to them via their Principal Investigator role. Among other things, this will help create a clean user experience.
- Allow bulk queries. It should be possible to efficiently generate a list of resources a given operator (user, role, or app) has access to, a list of operators who have access to a resource, and a list of permitted operations for a given operator/resource pair.
- Be multi-tenant compatible. No application should be required to grant unconditional trust to anything other than the central access control service.
Dalton, Mezzodaemon, and References
Medidata has already taken significant steps toward satisfying these requirements. We have built a canonical list of Medidata Roles to be used in configuration. The References service maps these roles to unique identifiers, allowing them to be used throughout the cloud. The Mezzodaemon service was designed to allow internal users to configure the set of possible role assignments for a given study-app combination. The Dalton service stored Mezzodaemon-compliant role assignments in the form of <operator, role, operable> triples. Together, these three services constituted a viable role-based access control system, but not one that would be sufficient for our platform as it grows.
The main element missing from this setup is the mapping of roles to permissions. In order to authorize a request, a service must internally determine the list of <operator, role, operable> triples that are applicable to this request. This means that the “inheritance” logic, even if implemented, would not be centralized and thus would neither be consistent nor friendly to a multi-tenant platform. Mezzodaemon’s mapping is limited and reflects a partially deprecated conception of our business requirements.
The Policy Machine Formalism
The Policy Machine is an attempt to rigorously describe the set of authorized capabilities on a platform. A privilege is defined by the triple <u, op, o>, where u is a user, op is one of a finite list of operations such as “delete” and o is a protected object such as a medical record (conveniently for us, access control literature has long had the convention of using medical records as its sample use case). Bob Smith is authorized to delete medical_record_564 if and only if the capability <Bob Smith, delete, medical_record_564> can be derived from the policy machine. Operations are organized into operation sets, overlapping collections of operations organized according to authorization rules.
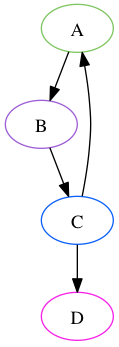
These capabilities are represented using a Directed Acyclic Graph. A directed graph is a set of nodes and edges, with each edge corresponding to an ordered pair of nodes. Two nodes A and B are considered “connected” if there exists a sequence of at least two nodes, starting with A and ending with B, such that each consecutive pair corresponds to an edge. This sequence is a “path”. A directed graph is acyclic when there is no node that is connected to itself.
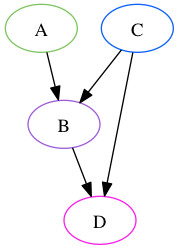
In the above graph, Nodes A and C are connected to node B directly, and to Node D through a path that includes B. C is also connected directly to D, so that if Node B were removed, C would remain connected. This is a Directed Acyclic Graph. The below graph contains a cycle from A to B to C to A, and thus is not acyclic.
In the Policy Machine Formalism, users, objects, and operation sets are nodes on a directed acyclic graph, as are two types of mediating nodes: user attributes, which correspond conceptually to roles, and object attributes, which can reflect any property of an object that is relevant to authorization, such as a unique identifier, a classification, or an association with another object. In the most basic version of the machine, a capability <u, op, o> can be derived if and only if an operation set ops exists such that:
- o is an element of ops
- u is connected to ops
-
ops is connected to o
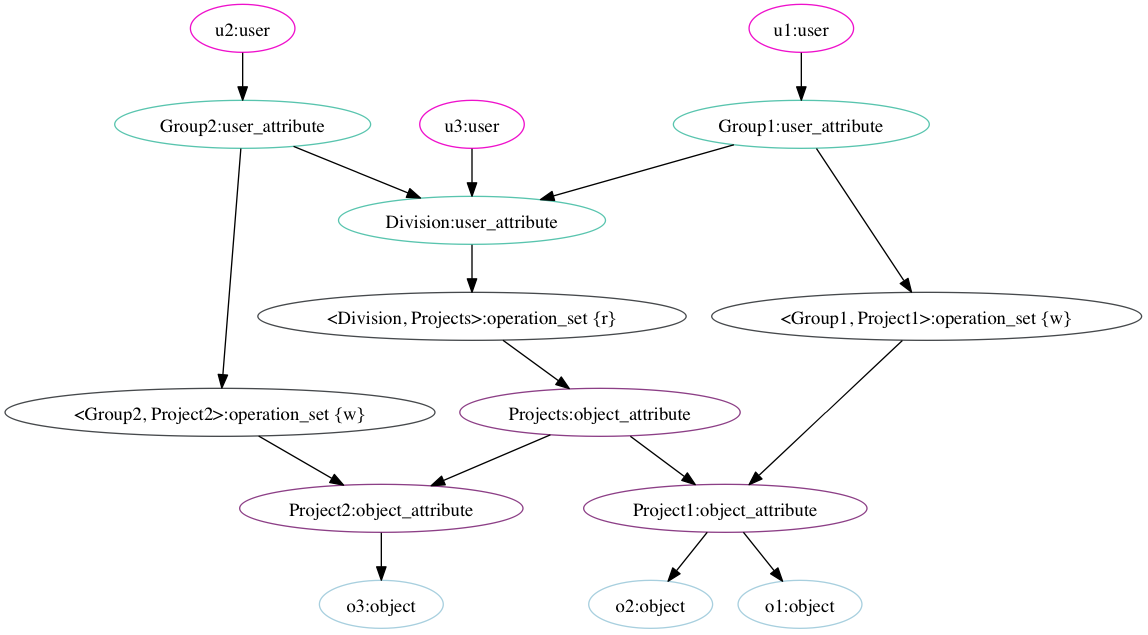
The graph above represents one possible access state for a policy machine. In this access state, the user “u1”, represented by the node in the top right corner, is connected to the <Division, Projects> operation set, which contains the “r” (“read”) operation. This same operation set is connected to all three objects o1, o2, and o3, represented by the nodes at the bottom of the graph. u1 thus has the capability to read each of those three objects. The path from u1 to the <Division, Project> operation set may be read as “u1 is part of Group 1, which is part of the Division, which is allowed to read each object belonging to any project” The path from the operation set to o3 may be read (working backwards) as “o3 is part of Project 2, which is a Project, so it is subject to the <Division, Project> operation set”.
The “w” (“write”) operation on an object is limited to users who are part of the Group that owns the Project that owns the object. u2 is connected to <Group2, Project2>, but not <Group1, Project1>, which authorizes u2 to write to o3 but not to either of the others. u1’s write permissions are the inverse. u3 is not connected to any operation set containing “w” and thus has no write capability on any object.
The policy machine state can be adjusted using “administrative operations.” Access control for administrative operations is represented using the same formalism as for other operations. This allows the policy machine to govern its own authorization.
Extensions and Interoperability
There are several optional elements to the policy machine specification that we do not anticipate substantially incorporating into the initial Medidata implementation. These include
* Prohibitions, in which a blacklist of operations is maintained alongside the capability whitelist.
* Obligations, in which triggered changes are made to the policy state in response to operations on objects
* Policy Classes, in which objects and attributes are divided into overlapping domains depending on which policy class nodes they are connected to on the graph.
We expect the initial build not to require prohibitions or obligations, and to include policy classes only to the nominal extent required by the specification. These elements are likely to be useful in the future for interoperability with other authorization systems, and may be added as needed. In particular, policy classes allow separate access control policies to be intersected rather than unioned, which is a common requirement.
Persistence
We are exploring various persistence options. A graph database seems like a natural fit, given the formalism. After benchmarking several solutions on graphs similar to the ones we expect to generate, Neo4j has emerged as a top contender. However, a directed acyclic graph can also be represented in a traditional relational database (see Twitter’s FlockDB, for example), or a NoSQL database, and this may actually be the more performant option as we can tailor the structure and indices to our specific requirements.
Special Queries
The various bulk query requirements can be conceptualized as representing “subtrees” of the policy graph, created by picking a single node as the root and traversing all paths, stopping on nodes of a specified type, which are treated as leaves. There has been extensive work on making such operations performant. The Policy Machine formalism also lends itself quite naturally to the requirement that users have the option to specify a single role on which to base access control decisions. Since each instance of a role assignment is represented in our machine as its own node, we can make the same capability determination on it as we would for a user node, in effect “chopping off” the root node of the user-permissions subtree and descending one level.
What We’re Building
We’ve created an open-source Ruby Gem that implements the Policy Machine formalism. It’s available at https://github.com/mdsol/the_policy_machine. The gem lets Ruby applications interact with the machine in a persistence-layer-agnostic way, which has allowed us to experiment with different kinds of databases.
We’re merging Mezzodaemon and Dalton into a new webservice that provides a RESTful API for the Policy Machine. We’ve taken advantage of our discoverable, RESTful platform architecture: Mezzodalton dynamically queries the other services in our platform to determine the inter-resource relations necessary to infer access rules, and caches the results. Mezzodaemon is thus able to build a broad map of our data and permissions state by treating all of our other services as a distributed graph.
We’re also building a role configuration UI (code-named Double Deuce) to allow users to define and edit roles within the clinical domains they’re adminstrating.
MezzoDalton is live as of April 25th as part of the Clinical Cloud’s 2014.1.0 release. It serves as the bouncer for several projects, including the new Audit and Core Clinical Objects services.

Further Reading