Hercules: Medidata's Data Migration Workhorse
As we build more services in the Clinical Cloud, there’s an increasing need for a robust tool to move large amounts of data between these services. Take Plinth, for example. Plinth is our core clinical objects service, serving resources like studies and sites. As more Medidata codebases adopt Plinth for master data management, they’ll need to migrate their own persisted core clinical objects over to Plinth.
Migration of large data sets is a relatively tough problem to crack:
- Migration choreography becomes an issue with large data sets with complex interdependencies. For example, studies should probably be migrated before assignments to those studies to assure relational integrity.
- Network hiccups during the migration process can lead to intermittent failures which shouldn’t bring the entire migration process to a halt.
- Good logging/reporting is required so that inevitable runtime problems can be quickly traced and fixed. So too, error reports should be written to make failed migrations easily repeatable.
- Authorization checks should be strictly enforced when migrating data to multi-tenant systems.
- We don’t want to migrate data directly to persistent stores. Rather, we want to invoke the rich validations and workflows exposed by Web services when creating or updating data in new systems.
Though there are several commercial or open source products (see a good review at http://apievangelist.com/2013/02/10/bringing-etl-to-the-masses-with-apis/), nothing we found met all of the criteria above. So we made our own tool and called it Hercules (aka ‘The Herc’). (Hercules can lift big things, get it?)
Hercules: Medidata’s Data Migration Workhorse
Hercules is a Web application built around some relatively simple concepts.
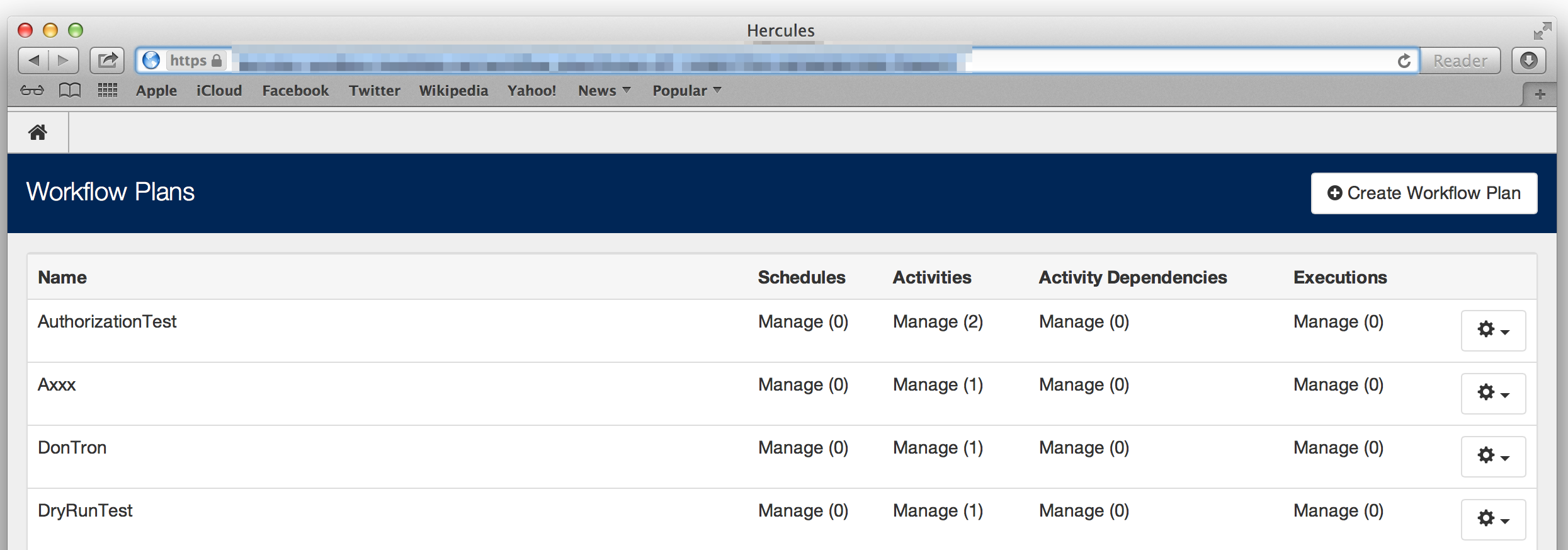
An activity is a unit of action in Hercules. An activity typically describes the migration of a resource from a source system to a destination (e.g. the migration of a set of studies from Rave – Medidata’s EDC/CDM System – to Plinth). Activities are implemented as well-tested classes which can be configured to get data from various sources and send it (after some transformation process), via Web services calls, to various platform destinations.
Activities are choreographed by means of activity dependencies. When one activity must be run before another, the user can create a dependency between the two. Hercules is smart enough to segment independent activities into groups which can be run in parallel, thus speeding the overall execution of the workflow plan. The Herc also prevents the user from avoiding circular dependencies between activities in a workflow plan. Cool!
Hercules is built on top of Amazon’s Simple Workflow Service (SWF). Once Hercules figures out the choreography of the various activities which make up a workflow plan, running the plan according to schedule is simply a matter of making the right calls to SWF at the right times. Hercules builds on the robustness, monitoring and workflow control that SWF already provides.
Finally, activities and their dependencies are packaged together into workflow plans. Hercules places authorization restrictions around workflow plans so that only authorized (and of course authenticated users) are allowed to execute those workflows. Users can clone these workflow plans to create similar plans quite easily.
During the execution of a workflow plan, users have quite a bit of insight into what’s going on. Hercules logs profusely and sends its logs to sumologic so users with sumo access can run queries to monitor live workflows (and write sumo alerts too). The Herc also allows you to run plans in ‘dry-run’ mode, which does everything but actually write data to persistent stores. Instead, during dry-run, Hercules will create an artifact describing what would have been persisted had such persistence been allowed. The user can scan this artifact for anything unusual before running the workflow for real.
And while I’m on the subject of executing workflows for real: Hercules produces an artifact describing the errors which occurred during the live execution of a workflow. This errors report is designed to serve as input to a re-execution of the workflow plan once the source of the errors has been identified and dealt with.
So Does Hercules Work?
Yes, it works really well. We’ve used it internally to move hundreds of thousands of records so far. The activity choreography engine made it easy for relatively non-technical users to specify activity dependencies, allowing Hercules to craft efficient workflows.
Of course, we occasionally ran into network hiccups and such during these data moves. The error artifacts worked as expected to help users re-run with ease requests which errored out.
Hercules’ Future
Hercules isn’t open source (yet). We will hopefully open-source a library (as a Ruby gem) to automatically compile activities and their dependencies into an optimized SWF workflow. Keep your eyes peeled.