Generating a Representative Data Set from Big Data
Over the past few years, Medidata has worked hard to meet the demanding requirements of producing high quality software applications. Building enterprise class solutions like a Big Data Analytics Platform involves testing huge amounts of clinical trial data from various studies, subjects, and embedded devices. Processing and storing terabytes or petabytes of data may take days or weeks to complete. Using a large data set during software development and testing delays the continuous integration and delivery efforts. We have taken an innovate approach on testing big data applications such as Extract, Transform and Load (“ETL”) process by using input space partition testing to create a smaller representative sample.
In an ETL process, data is extracted from an original data source (e.g., a MySQL database), and then is transformed into a structured format to support queries and analysis. Finally, the data is loaded into a target source (e.g., a PostgreSQL database) for customers to view. We compute, store, and analyze high volumes of clinical trial data through ETL processes using the Amazon Web Service (“AWS”). Specifically, we use the Hadoop-based service Amazon Elastic MapReduce (“EMR”) to process the data. Amazon EMR allows us to process hundreds of petabytes of clinical trial data much faster than with conventional methods. We also use Amazon Simple Storage Service (“S3”) and Redshift. S3 provides data storage infrastructure on the cloud and Redshift is a data warehouse service. A common scenario at Medidata is to have an ETL application that gets data from S3 or a database, then processes the data on EMR clusters, and then saves the transformed data to S3 or Redshift.
We have identified three problems when testing ETL software. First, we have huge amounts of clinical trial data from various studies, subjects, and embedded devices or monitors such as blood pressure, heart rate or body temperature. Even with EMR, processing petabytes of data takes days or weeks to complete. Running an entire or part of historical user data hinders the overall agile development process. Generating small and “representative” data sets for different data sources and clients quickly is challenging. We seek to find a smaller data set that represents from this larger set to satisfy domain-specific constraints, business constraints, referential constraints, statistical distribution, and other constraints. For brevity, we call this a representative data set. Second, data is transferred and transformed at different transition points during an ETL process. Should we validate the data at one point or all of them? Third, how should we validate transferred and transformed data? Manually validating high volumes of data is prohibitively costly, so this must be automated. This blog focuses on the first problem and the latter two will be addressed in a separate post.
Generating test data quickly, efficiently and accurately is important but complex to implement. We want engineers to develop applications using a small and representative data set because it will significantly shorten the development life cycle, hence allowing faster feedback during code commit. Often, data generation has had many issues such as fragmentation, duplication and with little clarity. Listed below are some of the challenges associated with testing large data sets.
- Generating different types of data formats including databases and json structures
- Generating a small and representative data set from source to satisfy different types of constraints including statistical analysis
- Generating data sets that reflect the continuous and on-going changes in business constraints
To solve the challenges, we developed an approach using input space partitioning in the big data context. We are developing a tool which implements this novel test generation method. Input space partition testing starts with an input-domain model (“IDM”). The tester partitions the IDM, selects test values from partitioned blocks, and applies combinatorial coverage criteria to generate test data. To the best of our knowledge, this is the first time space partition testing has been used to generate representative data sets derived from source in the big data context. In an agile process, testing applications with gigabytes or terabytes of data is expensive. Our test generator tool will ensure quality and significantly shorten testing and engineering cycles by giving immediate feedback on code without having to test terabytes of data. Using the tool saves time, costs, and manual efforts.
We also plan to use parallel computing and Hadoop to speed up data generation. Even if the process is slow, we only need to generate an initial representative data set once for a project. Then the data set will be refined incrementally to adjust to changing constraints and user values. Our initial prototype took 6 minutes to reduce 7 million database records down to hundreds, satisfying basic constraints such as edge case values and foreign key constraints. A savings of 99.99%!
From the figure below, a TDD or BDD software development cycle is typically broken down into three stages: pre-commit, commit, and post-commit. We have different projects written in different languages that share the same data sources. The data generator tool can be applied to any projects not yet developed or still at the pre-commit stage. The generated data set is used as the new independent derivation during testing and development iterations.
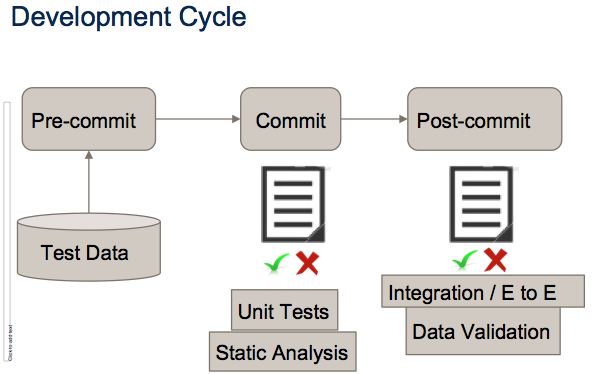
Using a representative data set at the pre-commit stage in TDD and BDD development helps provide faster feedback on the effects of code when a commit has been made. Using seeded test data with inputs derived from the test generator tool tightens the feedback loop where it now takes seconds and minutes to execute unit and integration tests instead of days or weeks. Developers and testers then can add a test, develop code, run test, refactor code and iterate more accurately and efficiently. This is a radical and innovative process transforming the way how testing is done for big data and it will replace long test cycle times.
The development of the data generator tool is the result of researching innovative techniques to tighten the feedback loop between commits, and as we continue to expand our data platform we will hopefully expand our tools for testing big data. Any feedback is welcome.